南京艾法益登信息技术有限公司
电 话:138-0516-7316
手 机:138-0516-7316
Q Q:手机微信
E-mail:13805167316@139.com
GPU (Graphics Processing Unit)属于通用图形处理器,由于采用多核并行计算的基础结构,且核心数非常多,可以支撑大量数据的并行计算;同时拥有数据高带宽高速访存,高浮点运算能力等特点,被广泛应用于深度学习AI模型的训练与推理,尤其在训练领域,英伟达的GPU方案目前占据垄断地位。
每2-3年,英伟达会推出新一代的GPU架构,从2008年的tesla到2018年的Volta再到最新推出的Ampere,通过架构的演进,每一代GPU的计算能力都会大幅提升,下面将会具体介绍英伟达GPU在AI方向的技术演进、架构创新、技术特点以及典型产品。
(1) 技术演进
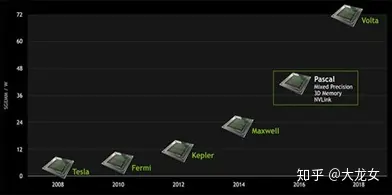
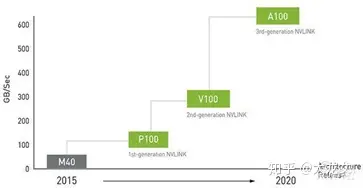
英伟达GPU系列在人工智能方向的技术演进主要从2016年P100开始,在此之前GPU主要是面向图形计算应用,因此AI相关计算效率并不高,2017年推出的V100芯片,英伟达首次引入了适用AI矩阵运算的Tensor core计算单元, 因此AI运算的峰值算力得到爆发式增长,而最新推出的A100芯片,又进一步改进了Tensor core的结构,使得AI峰值算力进一步得到提升。
随着算力的迅速增长,芯片的晶体管数量也迅速增加,从P100的153亿到V100的211亿再到A100的540亿,为了保证芯片的面积和功耗不随之大幅增加,流片工艺也从16nm演进到7nm,这也使得新推出的芯片价格屡创新高,相应使用成本大幅提升。更不容忽视的是,随着摩尔定律趋势逐渐放缓,算力增长有可能再次迎来新的瓶颈。
(2) 芯片架构设计
英伟达GPU系列的芯片架构经过Maxwell、Pascal、Volta以及Turing等多代演进,最新推出的Tesla A100芯片基于Ampere(安培)架构,如下图所示,芯片为多个SM单元(Streaming Multiprocessors,图中绿色部分,流式多处理器)构成的并发多核处理器,不同SM单元共享L2 Cache存储资源进行数据访存,A100的安培架构中有128个SM核,SM结构是芯片架构升级的核心。
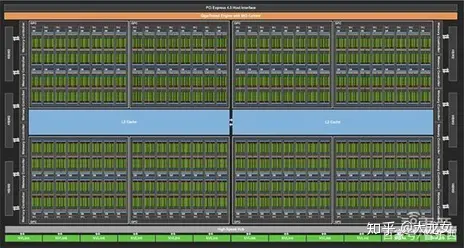
A100安培架构示意图
每一次架构的升级也就意味着SM单元的优化,下图所示为A100芯片中SM单元的架构图。与上一代Volta、Turing架构相比,安培架构中SM的计算能力增加了2倍以上,这主要是归结于Tensor Core单元功能的大幅升级。
Tensor Core是英伟达GPU架构中专为深度学习矩阵运算设置的张量计算单元,目前已经演进到第三代。如下图所示,A100芯片每个SM中含有4个第三代Tensor Core,相比上一代的FP16/FP32混合精度计算,这一代Tensor Core 除了支持 FP32 和 FP16 外,引入新的精度 TF32 和 FP64,并支持混合精度 BF16/FP16 以及 INT8、INT4、Binary。
新精度的引入是A100的深度学习运算效率提高的关键之一。FP32 是当前深度学习训练和推理中最常用的格式,新精度TF32和FP32一样都拥有 8 个指数位,能支持相同的数字范围,但尾数位相比FP32进行了部分删减和 FP16 一样是 10 个,该精度水平高于 AI 工作负载要求。而TF32和FP32的工作方式相似,数据支持相互转换,TF32 Tensor Core 根据 FP32 数据的输入转换成 TF32 格式后进行运算,最后输出 FP32 格式的结果,实际效果相当于FP32精度计算。借助TF32精度减轻运算消耗,A100 单精度训练峰值算力提升至 156 TFLOPS,是上一代V100芯片 FP32算力 的 10 倍。
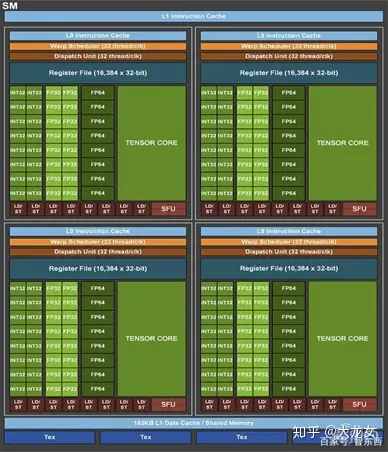
A100 SM单元架构示意图
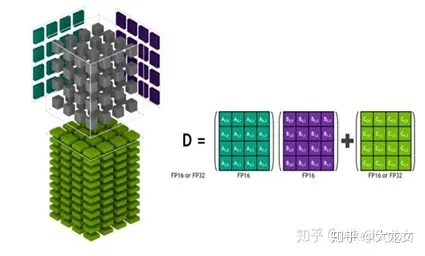
而另一个运算效率提高的关键是第三代Tensor Core的结构化稀疏特性,稀疏方法是指通过从神经网络中提取尽可能多不需要的参数,来压缩神经网络计算量。Tensor Core的矩阵稀疏加速原理如下图所示,首先对计算模型做 50% 稀疏,稀疏化后不重要的参数置0,之后通过稀疏指令,在进行矩阵运算时,矩阵中每一行只有非零值的元素与另一矩阵相应元素匹配,这将计算转换成一个更小的密集矩阵乘法,实现 2 倍的加速。这一特性可提供高达 2 倍的峰值吞吐量,同时不会牺牲深度学习核心矩阵乘法累加作业的准确率。

A100 稀疏矩阵运算示意图
(3) 技术特点
1. Tensor Core(张量核心单元)
深度神经网络的训练和推理过程中存在大量的卷积运算操作,将三维的卷积核在输入通道方向展开成2维结构,同时feature map也根据卷积核的展开形式打平成对应的2维矩阵,两者进行标准的矩阵乘累加运算就可以实现该卷积操作。因此深度学习模型的计算加速可以转化为通用矩阵乘法加速。
从Volta架构开始,英伟达GPU引入专门的张量核心单元,对神经网络矩阵乘法进行加速。Volta和Turing架构中的Tensor Core在进行深度学习训练时,采用FP16/FP32混合精度的加速方案,基于volta架构的Tesla V100每周期峰值计算能力为125Tensor Tflops,是上一代未采用张量核心单元,基于Pascal架构Tesla P100芯片 FP32峰值算力的12倍。
而最新的Ampere架构进一步优化了Tensor Core单元的性能,引入新的精度 TF32 和 FP64,支持混合精度 BF16/FP16 以及 INT8、INT4、Binary。并增加稀疏化矩阵的加速运算功能。Ampere架构下的Tesla A100芯片单精度FP32训练峰值算力提升至 312 TFLOPS,是Tesla V100芯片 FP32峰值算力 的 20 倍。
由此可以看出Tensor Core单元是英伟达GPU系列深度学习运算加速的核心,也是每一代新架构AI计算性能提升的关键。
2. HBM(高带宽存储单元)
高带宽存储器(HighBandwidth Memory,HBM),可提供最高12倍于DDR4的带宽,是目前最先进的存储技术之一。高并行度的深度学习运算存在大量的数据访存需求,为了实现数据的高效并发读写,Tesla V100架构集成HBM2存储,16GB的GPU内存可以提供峰值达到900 GB/s 的内存带宽,从一定程度上缓解了深度学习运算中的访存瓶颈。
3. 功能完备,通用性非常好,拥有丰富计算单元,支持各种精度的高效并行运算。
4. 晶体管数量规模大,为了控制芯片功耗与面积,芯片流片工艺必须和架构一起升级,
成本昂贵,并且良率难以控制。

(4) 典型产品
英伟达系列GPU产品中,目前用于云端训练的主流产品有Tesla V100以及最新推出的Tesla A100. 用于云端推理的有Tesla T4以及用于边缘推理的Jetson系列。
2017年推出的Tesla V100 基于Volta架构,FP32浮点性能16.4TFLOPS,FP16性能32.8 TFLOPS,AI混合精度性能125 TFLOPS , 不支持INT8和INT4计算,整体功耗为300W。Tesla A100基于Ampere架构,是英伟达最新发布的云端训练GPU产品,FP32浮点性能19.5TFLOPS,FP16性能78TFLOPS,TF32 Tensor Core 峰值性能 312 TFLOPS,INT8算力1,248 TOPS,INT4算力2,496 TOPS,整体功耗为400W。
Tesla T4基于Turing 架构,该架构也引入的Tensor Core(张量单元)。该架构在Tensor Core中设计了为推理而使用的INT8和INT4的精度模式。FP16也完全支持需要更高精度的工作负载。Tensor Core加速矩阵乘法运算,是神经网络训练和推理的核心计算,相比volta架构,Turing架构的 Tensor Core更加擅长推理。
TeslaT4 GPU包括2560个CUDA核心和320个Tensor核心,FP32浮点性能8.1 TFLOPS,Tensor混合精度性能65TFLOPS,INT8算力130TOPS,INT4算力260TOPS。显存方面,Tesla T4配备了16GB GDDR6显存,显存带宽为320GB/s。整体功耗为75W,和CPU相比,T4可以提供超达40倍的推理性能。
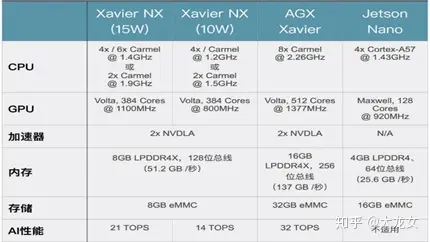
用于边缘推理的Jetson系列,采用低功耗GPU对神经网络推理进行加速, Xavier NX产品中GPU采用Volta架构,为了降低成本,边缘端使用的加速架构通常会和云端相差一至两代。
值得注意的是英伟达最新推出的NVIDIA EGX A100,采用安培架构,它被设计为插入现有边缘数据中心,以帮助管理边缘附近的数据,该场景介于云端数据中心和边缘终端设备两者之间,可以作为云边端协同的纽带。